在 2026 年,AI 应用开发已进入“Agentic Workflow(智能体工作流)”爆发期。对于开发者而言,API 不再只是一个对话接口,而是驱动复杂业务逻辑的底层引擎。对于开发者来说,选择一个合适的LLM API,不再只是看模型能力,还要考虑调用成本、稳定性、风控限制以及全球可用性。
这篇文章将从基础认知出发,带你系统了解2026年主流LLM API,并重点讲清楚:如何在真实业务中稳定调用这些模型。
一、 LLM API 是什么?
LLM API(Large Language Model API),本质上是各大AI厂商对外提供的大模型调用接口。开发者无需自行训练模型,只需通过HTTP请求,即可完成文本生成、对话、代码生成、数据分析等复杂任务。
常见的调用方式包括:
- 文本生成(Chat / Completion)
- Embedding向量生成(用于搜索/RAG)
- 多模态能力(图像/音频/视频理解)
- Agent调用(工具执行 / function calling)
简单来说,LLM API让开发者可以像调用“云服务”一样调用AI能力。
二、2026十大主流LLM API推荐与对比
1. OpenAI(GPT-5 / o2 系列):依然是全能王者
2026 年的 GPT-5 在推理能力、指令遵循、多语言支持上依然处于第一梯队。o2 系列强化了代码生成和数学推理,适合需要高精度输出的场景。
- 上下文:256K(部分版本支持 1M)
- 多模态:支持图像、音频输入
- 价格参考:输入 $2.5 / 1M tokens,输出 $10 / 1M
- 适合场景:通用对话、代码生成、复杂推理、Agent 开发
2. Anthropic(Claude 4):人类价值观对齐与长文档处理
Claude 系列一直以“安全、可控、长上下文”著称。Claude 4 将上下文扩展到了 2M token,可以直接处理整本《三体》三部曲级别的长文档。在需要严格遵循指令、避免有害输出的场景下,Claude 表现优于大多数竞品。
- 上下文:2M
- 多模态:不支持(但可读取图像中的文字)
- 价格参考:输入 $3 / 1M,输出 $15 / 1M
- 适合场景:长文档分析、法律/医疗合规问答、内容审核
3. Google(Gemini 2.5 Ultra):强大的多模态原生能力与生态集成
Gemini 2.5 Ultra 是真正的多模态模型——原生支持图像、视频、音频、文本的混合输入。如果你需要分析 YouTube 视频、处理图文混合的 PDF,或者做跨模态检索,Gemini 是首选。此外,它与 Google Drive、Gmail、YouTube 的深度集成,让自动化工作流变得非常方便。
- 上下文:1M
- 多模态:原生支持(图像、视频、音频)
- 价格参考:输入 $0.5 / 1M,输出 $2 / 1M
- 适合场景:多媒体内容分析、Google 生态自动化、多模态 RAG
4. Meta(Llama 4 API):开源生态的顶峰,高性价比
Llama 4 虽然开源,但 Meta 官方和第三方平台(如 Together AI、Groq、Replicate)都提供了 API。它的能力接近 GPT-5,但价格低一个数量级。对于成本敏感、又不想牺牲太多性能的团队,Llama 4 是最务实的选择。
- 上下文:128K(部分微调版本支持更长)
- 多模态:基础版本仅文本,社区版有多模态变体
- 价格参考:输入 $0.2 / 1M,输出 $0.4 / 1M
- 适合场景:大批量推理、成本敏感型应用、本地化部署备选
5. Mistral(Large 3):欧洲最强模型,隐私保护机制
Mistral Large 3 在推理能力和多语言表现上仅次于 GPT-5,但它的卖点是隐私:Mistral 提供欧洲数据主权合规选项,数据不离开欧盟。对于有 GDPR 严格要求的业务,这是 OpenAI 和 Google 之外的可靠选择。
- 上下文:128K
- 多模态:不支持
- 价格参考:输入 $2 / 1M,输出 $6 / 1M
- 适合场景:欧盟合规业务、企业私有数据处理、多语言应用
6. DeepSeek(V4):高性价比与极强的逻辑推理能力
DeepSeek V4 延续了前代“便宜又大碗”的特点,同时在数学、代码、逻辑推理上达到了接近 GPT-5 的水平。1M 的上下文窗口和极低的定价(约 $0.14 / 1M 输入),让它成为长文本处理场景的性价比之王。
- 上下文:1M
- 多模态:不支持
- 价格参考:输入 $0.14 / 1M,输出 $0.28 / 1M
- 适合场景:长文档摘要、代码解释、学术论文处理
7. Groq(LPU 推理加速 API):极速响应的首选
Groq 不做自己的模型,而是提供极快的推理硬件(LPU)。你可以通过 Groq API 运行 Llama、Mistral 等开源模型,得到 每秒数百甚至上千 token 的生成速度。对于需要实时交互(如语音助手、实时翻译)的场景,Groq 几乎没有对手。
- 上下文:取决于所运行的基础模型
- 多模态:取决于模型
- 价格参考:按请求次数 + token 混合计费,比裸模型略贵,但速度快 5-10 倍
- 适合场景:实时对话、流式输出、低延迟应用
8. X.AI(Grok-3):实时信息获取与独特的语料库
Grok 的最大特点是实时联网。它默认会检索 X(Twitter)上的最新信息,适合需要追踪热点、分析舆论、获取实时数据的场景。此外,Grok 的语料库带有独特的网络文化色彩,回答风格比主流模型更“鲜活”。
- 上下文:256K
- 多模态:支持图像输入
- 价格参考:X Premium+ 订阅包含,API 单独计价约 $2 / 1M 输入
- 适合场景:舆情监控、实时信息查询、社交媒体内容生成
9. Amazon Titan(Nova 系列):AWS 生态深度集成
Titan Nova 系列是 Amazon 2025 年底推出的新一代模型,通过 AWS Bedrock 提供。它的优势不是单项能力最强,而是与 AWS 服务(S3、Lambda、Glue 等)的无缝集成。如果你的业务已经跑在 AWS 上,Titan 可以帮你省去大量数据搬家和集成工作。
- 上下文:256K
- 多模态:支持
- 价格参考:输入 $0.8 / 1M,输出 $2.5 / 1M(Bedrock 统一计费)
- 适合场景:AWS 原生应用、企业级数据处理、与云服务深度耦合的业务
10. Cohere:企业级搜索与 RAG 的最佳实践
Cohere 不做通用聊天模型,而是专注于 RAG(检索增强生成)和语义搜索。它的 API 内置了重排序、文档索引、引用溯源等功能,可以大幅降低企业构建知识库问答系统的门槛。
- 上下文:128K
- 多模态:不支持
- 价格参考:按请求量阶梯计价,企业版另议
- 适合场景:企业内部知识库、客服机器人、文档检索与生成
三、2026 开发者调用指南:如何构建稳定环境?
上面列了 10 个 API,各有各的强项。选对了模型,不代表应用就能稳健运行。许多开发者在本地测试时一切正常,一旦部署到生产环境进行高并发调用,就会频繁遇到“API 请求失败”或“连接重置”。
1、为什么 API 调用也会被风控?
LLM API 服务商(尤其是 OpenAI、Anthropic、Google)会监控每一次请求的来源。主要原因有:
- 地域合规:某些模型只能在特定地区提供服务(比如 Claude 4 不对部分国家开放)。
- 防滥用:防止恶意爬取、批量注册、API 密钥被盗用后的大规模调用。
- 负载控制:对非正常的高频请求做限制,保护服务质量。
具体到技术层面,风控系统会检查几个维度:
(1)IP 信誉(Reputation)
如果你的请求来源 IP 是数据中心 IP(比如阿里云、AWS、DigitalOcean 的机房 IP),很多 API 会直接拒绝或降低速率限制。因为这些 IP 段经常被用于爬虫、自动化攻击,信誉分很低。
(2)请求分布异常
一个 API 密钥在短时间内从同一个 IP 发起大量请求,或者请求模式过于规律(比如每 5 秒一次,分秒不差),会被判定为机器人行为。
(3)数据中心 IP 特征明显
除了 IP 归属 ASN,风控还会检查反向 DNS、路由跳数、甚至 TCP 握手指纹(JA3/JA4)。普通家庭宽带的特征和机房服务器明显不同。
2、如何优化调用环境?
针对上面几个原因,解决方案也很直接:
(1)使用更接近真实用户的网络环境
把请求来源从数据中心 IP 换成住宅 IP(ISP 分配的真实家庭宽带 IP)或移动 IP(4G/5G 基站 IP)。这些 IP 的信誉分高,被限流的概率低很多。
在实际部署中,越来越多团队会通过住宅 IP / ISP 代理网络(如 IPFoxy住宅IP服务)来优化 API调用环境,降低封禁与限流风险。这类服务提供真实家庭 IP 池,支持按地区筛选(美国、欧洲、日本等),并且可以做到 IP 轮换和粘性会话,兼顾稳定性和分散性。
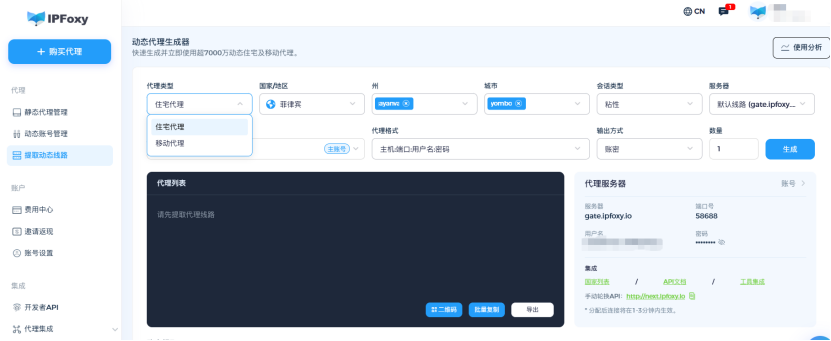
(2)分散请求来源
如果有大量请求需要发出,不要让它们都挤在同一个 IP 上。可以使用代理池,按轮询或负载均衡的方式分散到多个 IP。
(3)降低自动化识别概率
在请求之间加入随机延迟(比如 0.5–2 秒的 jitter),避免固定的时间间隔。还可以随机化 HTTP 请求头(User-Agent、Accept-Language 等),让请求看起来更像真实浏览器发出的。
四、 结语
2026 年的 AI 应用开发,不仅是代码逻辑的较量,更是基础设施稳定性的比拼。选择合适的 LLM API 只是第一步,建立一个稳定调用环境,才是保障业务连续性的基石。在奔向通用人工智能(AGI)的道路上,稳健的网络底层将是你应用最坚实的后盾。

