在数据驱动的内容生态中,YouTube数据抓取已成为开发者和运营人员的重要工具。无论是视频分析、关键词研究,还是竞品监控,都离不开高效的数据采集能力。
本指南将从基础概念到实战开发,系统讲解如何使用 Python + Playwright 构建稳定的 YouTube 爬虫,包括数据获取方式、代码实现以及防封策略,帮助你快速搭建可用的数据抓取方案。
一、什么是YouTube数据抓取?
在2026年,随着视频内容竞争不断加剧,YouTube已经成为数据分析、内容研究和营销决策的重要来源。越来越多开发者和运营团队开始关注YouTube数据抓取(YouTube Data Scraping),用于获取视频、评论、频道等关键数据。
所谓YouTube数据抓取,是指通过程序自动访问YouTube网页或官方接口(API),批量提取结构化数据的过程。而在实际开发中,最常用的实现方式就是基于 Python 的YouTube爬虫。
与手动浏览相比,爬虫可以在短时间内完成大规模数据采集,例如:
- 视频标题、播放量、点赞数
- 评论内容与用户互动数据
- 频道信息与内容更新频率
这使得YouTube数据抓取被广泛应用于内容分析、竞品研究以及自动化数据处理等场景。
不过,需要注意的是,随着平台风控不断加强,单纯依赖基础爬虫已经很难稳定获取数据。如何在保证效率的同时避免被封,成为YouTube数据抓取中必须解决的核心问题。
二、YouTube可以抓取哪些数据?
在进行YouTube数据抓取之前,首先需要明确可以采集哪些数据类型。不同的数据对应不同的应用场景,是构建Python YouTube爬虫时的重要基础。通常来说,YouTube数据采集主要分为以下三类:
1. 视频数据抓取
通过抓取视频数据,可以用于内容分析、爆款视频挖掘以及关键词研究。视频数据通常包括:
- 视频标题与描述
- 播放量、点赞数、评论数
- 标签(Tags)与分类
- 发布时间
2. 评论数据抓取
通过批量抓取评论数据,可以进行舆情分析、用户需求挖掘以及情绪分析。评论数据通常包括:
- 评论内容
- 评论点赞数
- 回复内容与结构
3. 频道数据抓取
频道数据可以帮助你评估账号表现、制定内容策略或进行竞品分析,频道数据主要包括:
- 频道名称与简介
- 订阅人数
- 视频发布数量
- 更新频率与内容类型
三、Python抓取YouTube数据的两种方法
在实际开发Python YouTube爬虫时,常见的数据获取方式主要有两种:通过官方API获取数据,以及通过爬虫直接抓取页面数据,可以根据需求进行选择。
1、使用YouTube Data API获取数据
YouTube官方提供了Data API,允许开发者通过接口获取平台上的部分数据。这是一种较为规范的YouTube数据采集方式。
优点:
- 数据结构清晰,稳定性高
- 不容易触发反爬机制
- 官方支持,合规性更好
缺点:
- 请求次数有限制(配额限制)
- 可获取的数据字段较少
- 某些数据无法直接访问
因此,API更适合轻量级或合规要求较高的项目。
2、使用Python爬虫抓取页面数据
相比API,直接通过爬虫抓取页面数据是更灵活的方式。
常见实现方式包括:
- 使用 requests 发送HTTP请求
- 解析返回的HTML或JSON数据
- 使用 Selenium 处理动态加载内容
优点:
- 数据获取更全面
- 灵活性高,可定制化强
- 不受官方接口字段限制
缺点:
- 容易触发反爬机制
- 开发和维护成本更高
- 稳定性依赖抓取策略
3、API与爬虫方式对比
在实际选择时,可以通过以下对比来判断哪种方式更适合你的需求:
| 对比项 | YouTube Data API | Python爬虫抓取 |
| 数据来源 | 官方接口 | 页面HTML / 接口数据 |
| 数据完整性 | 较有限 | 更全面 |
| 开发难度 | 较低 | 中等偏高 |
| 稳定性 | 高 | 依赖策略 |
| 是否易被封 | 不易 | 容易触发反爬 |
| 请求限制 | 有配额限制 | 无固定限制 |
| 灵活性 | 较低 | 高 |
| 适用场景 | 轻量数据获取 | 大规模数据采集 |
四、Python实战:如何抓取YouTube视频数据
在了解了基本原理之后,接下来通过一个更稳定的方案,演示如何使用 Playwright + Python 实现YouTube数据抓取。
相比 requests 和 Selenium,Playwright 可以模拟真实浏览器环境,有效应对 YouTube 的动态渲染和反爬机制,更适合实际项目使用。
1. 安装
首先安装 Playwright:
pip install playwright
playwright install2. 启动浏览器并访问页面
from playwright.sync_api import sync_playwright
url = "https://www.youtube.com/watch?v=VIDEO_ID"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True) # 可改为 False 观察浏览器行为
page = browser.new_page()
try:
page.goto(url, timeout=60000)
# YouTube 不建议仅使用 networkidle,可能一直加载
page.wait_for_selector("video", timeout=10000)
except Exception as e:
print("页面加载失败:", e)
browser.close()
exit()
html = page.content()
print(html[:1000])
browser.close()建议:
headless=True表示无头模式(适合服务器运行)- 建议使用
wait_for_selector替代networkidle,在 YouTube 页面更稳定 - 相比
requests,这里获取的是渲染后的完整DOM
3. 提取视频数据
Playwright可以直接执行JS,获取页面中的全局变量:
from playwright.sync_api import sync_playwright
url = "https://www.youtube.com/watch?v=VIDEO_ID"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
try:
page.goto(url, timeout=60000)
page.wait_for_selector("video", timeout=10000)
except Exception as e:
print("页面加载失败:", e)
browser.close()
exit()
title = None
views = None
try:
data = page.evaluate("() => window.ytInitialPlayerResponse")
if not data:
print("未获取到数据,可能被限制或页面未加载完成")
browser.close()
exit()
title = data["videoDetails"]["title"]
views = int(data["videoDetails"]["viewCount"])
print("标题:", title)
print("播放量:", views)
except Exception as e:
print("数据获取失败:", e)
browser.close()
exit()
browser.close()说明:
- 直接读取
window.ytInitialPlayerResponse,比正则解析更稳定 - 避免HTML解析带来的结构风险
- 增加异常处理,防止程序崩溃
- 注意:在部分地区或风控情况下,该变量可能为空
4. 数据存储
import json
if not title or not views:
print("数据不完整,终止保存")
exit()
video_data = {
"title": title,
"views": views
}
with open("youtube_data.json", "w", encoding="utf-8") as f:
json.dump(video_data, f, ensure_ascii=False, indent=4)五、YouTube数据抓取如何避免被封?稳定爬虫与反封策略
抓取 YouTube 数据时,常见问题是 IP封禁、验证码和数据不全。稳定抓取的核心是:控制请求特征 + 分散来源 + 模拟真实环境。
1.使用动态住宅代理IP
YouTube 会基于 IP行为 进行风控,因此使用代理IP是稳定抓取的关键。
推荐使用高质量的动态住宅代理,如果IP重复率高或被滥用,很容易触发限制。因此,通常会选择像 IPFoxy 这类提供优质动态住宅代理服务,通过广泛且干净的IP池子配合灵活的轮换机制,来降低请求被识别的概率。同时可以根据不同任务设置出口地区或切换策略,适配不同的数据抓取需求。
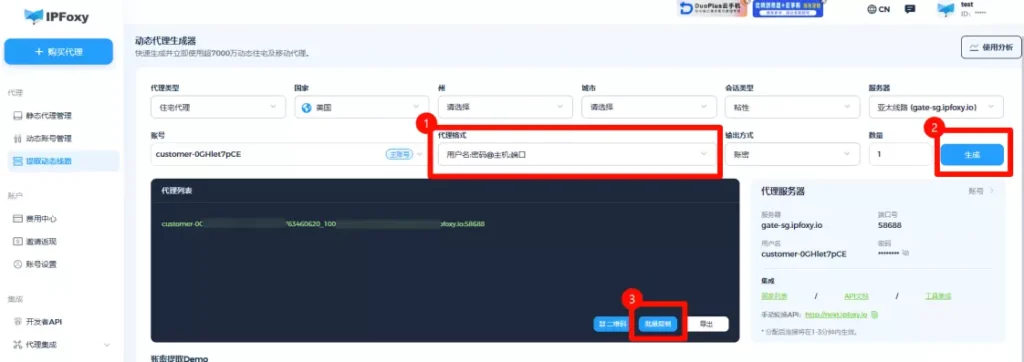
以下是IPFoxy代理IP示例(Python)
可以通过IPFoxy动态IP面板设置IP所需参数,并生成可配置的代理信息粘贴到python代码上,例如代理连接信息是:username:password@gate-us-ipfoxy.io:58688,那么代码示例为:
import urllib.request
proxy = urllib.request.ProxyHandler({
'https': 'username:password@gate-us-ipfoxy.io:58688',
'http': 'username:password@gate-us-ipfoxy.io:58688',
})
opener = urllib.request.build_opener(proxy)
urllib.request.install_opener(opener)
response = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(response)如果执行代码看到出口IP发生变化,说明代理已成功生效。接下来可以在 Playwright 中使用代理:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={
"server": "http://gate-us-ipfoxy.io:58688",
"username": "username",
"password": "password"
}
)2. 控制请求频率
高频请求是触发封禁的主要原因,建议单IP请求间隔 ≥ 3 秒,增加随机延迟并避免连续快速访问多个视频
import time, random
def random_delay():
time.sleep(random.uniform(2, 5))
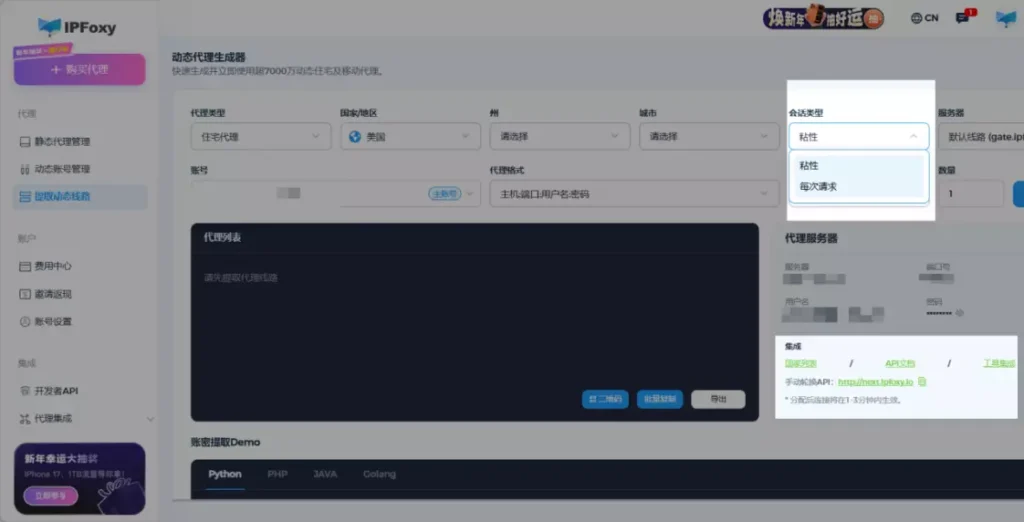
random_delay()可以通过IPFoxy动态代理生成器配置IP轮换策略,可以根据不同抓取场景灵活配置:
- 粘性会话(Sticky Session):适合需要连续访问同一视频或频道的场景(如分页加载、评论抓取)。可以在30分钟-24小时自主配置,避免频繁切换影响数据完整性。
- 按请求轮换(Rotating per Request):适用于批量抓取多个视频或搜索结果页,每次请求自动切换IP,有效分散请求来源,降低高频访问带来的风控风险。
- 手动切换:在遇到异常页面(如验证码或访问限制)时,或是单IP请求间隔不匹配粘性会话与按请求轮换两种模式,可以通过API主动切换。
3. 模拟真实浏览器行为
仅使用代理还不够,YouTube还会检测浏览器行为。
建议设置 User-Agent,等待关键元素加载并模拟用户操作(滚动/停留),避免使用纯HTTP请求(如requests)进行大规模抓取
page = browser.new_page(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
page.goto(url)
page.wait_for_selector("video")4. 控制采集规模
很多人可能会忽略采集规模,其实不同规模需要不同方案:
| 规模 | 推荐方案 |
| <100条 | Playwright + 单IP |
| 100~1万 | Playwright + 动态代理 |
| 1万+ | 分布式 + IP池 + 调度系统 |
六、常见问题
Playwright 更适合动态网站抓取,支持 JavaScript 渲染和真实浏览器环境,抗封能力较强;Selenium 更适合传统自动化测试。
小规模测试可以,但中到大规模抓取几乎不可行。代理能隐藏真实IP,降低被封概率。
JSON 或 CSV 都可,JSON 更适合嵌套数据结构,CSV 更适合表格化分析。保存前建议检查数据完整性。
总结
通过本文,你已经掌握了从基础原理到实战代码的完整 YouTube数据抓取流程,并了解了在实际项目中如何通过代理IP、请求控制和浏览器模拟来提升稳定性。
如果你需要进一步扩展,可以继续深入评论抓取、搜索页采集或分布式爬虫方案。合理选择技术方案并优化抓取策略,才能在保证稳定性的前提下,实现长期可用的数据采集系统。

