在 2026 年的爬虫开发,浏览器自动化工具已经成为主流方案。其中,Playwright 和 Puppeteer 是最常被提及的两大框架。很多开发者在选型时都会面临同一个问题:两者到底有什么区别?在真实项目中该如何选择?
本文将从功能特性、开发体验以及实际爬虫场景出发,对 Playwright 与 Puppeteer 进行系统性对比,帮助你在不同业务需求下做出更合适的技术决策。
一、什么是Playwrigh?
Playwright 是由 Microsoft 推出的开源浏览器自动化框架,主要用于网页自动化测试和数据采集(爬虫)等场景。它可以通过代码控制浏览器执行真实用户操作,例如页面访问、点击按钮、填写表单以及抓取网页数据,因此在自动化与爬虫领域被广泛应用。
核心特点
- 多浏览器支持:Playwright 支持 Chromium、Firefox 和 WebKit 三大主流浏览器内核。
- 自动等待机制:Playwright 内置自动等待功能,在元素加载完成后再执行操作。
- 更接近真实用户行为:Playwright 的执行逻辑更贴近真实用户操作流程。
- 多语言支持:Playwright 支持多种主流编程语言,开发者可以根据自身技术栈灵活选择。
二、什么是Puppeteer?
Puppeteer 是由 Google 推出的浏览器自动化工具。是基于 Node.js 开发,通过提供一套简洁的 API,让开发者可以轻松实现网页自动化操作和数据采集任务。
核心特点
- 专注 Chromium 浏览器:Puppeteer适合针对 Chrome 环境的自动化任务。
- API 简洁易用:Puppeteer 提供了直观的编程接口,对于初学者来说,上手门槛相对较低。
- 强大的页面控制能力:Puppeteer 可以精细控制浏览器行为,非常实用。
- 成熟的社区生态:Puppeteer 积累了大量开发者和开源资源,方便快速查阅和使用。

三、深度对比Playwright与Puppeteer
在本节中,从多个维度,对 Playwright 和 Puppeteer 进行更直观的对比。通过结合示例代码,你可以更清晰地理解两者在实际使用中的差异。
1. 语言支持
- Puppeteer 主要面向 JavaScript 和 TypeScript 开发者。
- Playwright支持 JavaScript、Python、Java 和 .NET 等多种语言。
2. 浏览器支持
在浏览器支持方面:
- Puppeteer:以 Chromium 为核心,对 Firefox 支持有限
- Playwright:支持 Chromium、Firefox、WebKit,覆盖主流浏览器环境
3. 爬虫开发体验对比
在实际开发中,两者的差异不仅体现在功能上,也体现在代码结构和设计理念上。
Puppeteer:结构简单,但需要手动控制较多
以下是一个标准的 Puppeteer 爬虫脚本:
const puppeteer = require('puppeteer');
async function run() {
// 1. 启动无头浏览器并创建新页面
const browser = await puppeteer.launch({ headless: "new" });
const page = await browser.newPage();
// 2. 导航至目标 URL
await page.goto('https://example.com');
// 3. 显式等待:在 Puppeteer 中,你必须手动声明等待逻辑,否则脚本会因页面未加载完而崩溃
await page.waitForSelector('.title');
// 4. 元素提取
const text = await page.$eval('.title', el => el.innerText);
console.log(`抓取到的标题是: ${text}`);
// 5. 释放资源
await browser.close();
}
run();分析:在此片段中,puppeteer 库被引入脚本。你定义了一个异步函数,手动创建浏览器实例和页面。关键点在于第 3 步,你必须显式调用 waitForSelector,这种“手动挡”模式虽然灵活,但在面对动态 DOM 时,代码量会迅速增加。
Playwright:智能的自动化模式
相比之下,Playwright 的代码更符合快速化需求:
const { chromium } = require('playwright');
async function run() {
// 1. 启动浏览器并引入 BrowserContext 环境隔离
const browser = await chromium.launch();
const context = await browser.newContext(); // 创建独立的上下文,Cookie 和缓存完全隔离
const page = await context.newPage();
await page.goto('https://example.com');
// 2. 自动等待:Playwright 会自动执行可操作性检查(可见、稳定、非遮挡)
const text = await page.locator('.title').innerText();
console.log(`抓取到的标题是: ${text}`);
await browser.close();
}
run();分析:在 Playwright 脚本中,我们使用了 newContext()。这种架构允许你在不重启浏览器的情况下开启多个相互隔离的任务,极大提升了并发性能。更重要的是,第 2 步中没有 wait 代码——Playwright 的 locator API 内置了自动等待机制,它会在执行操作前自动确认元素是否已挂载并可见。
4. 性能与执行效率
- Puppeteer:在轻量级任务中表现稳定,但在高并发或复杂页面下需要额外优化
- Playwright:在多页面、多任务场景下性能更优,资源管理更高效
5. 自动等待机制
- Puppeteer:以手动等待为主,需要开发者自行控制元素加载、页面跳转等时机,灵活性高,但在复杂页面中容易遗漏等待条件
- Playwright:内置自动等待机制,在执行操作前会自动判断元素是否可交互,减少报错,提升爬虫稳定性
6.推荐使用场景
为了帮助你快速决策,我们汇总为以下选型建议表。无论你是追求极致的工程化效率,还是专注于特定生态的轻量级开发,都能从中找到最适合的工具。
| 需求场景 | 推荐工具 | 原因 |
| 大规模、跨语言数据采集 | Playwright | 跨浏览器支持、更强的并行性能、原生 Python 支持 |
| 复杂的 SPA 应用(React/Vue) | Playwright | 强大的自动等待机制与 Shadow DOM 穿透 |
| 轻量级、单一 Chrome 自动化 | Puppeteer | 纯粹的 Node.js 生态、更小的学习心智负担 |
| 老旧项目维护/与 Jest 集成 | Puppeteer | 极其成熟的社区积累与插件支持 |
四、如何提升爬虫与自动化脚本成功率?
在真实的爬虫项目中,影响成功率的核心并不是“能不能抓到数据”,而是能否持续、稳定、不被封地抓取数据。尤其是在电商、社交媒体、地图类站点中,风控机制往往比页面结构更复杂。
很多开发者会遇到:小规模测试没问题,一旦扩大采集规模就开始频繁失败。这通常是因为触发了网站的反爬策略。
1. 为什么自动化脚本在大规模任务中容易失败?
当爬虫从“单机测试”进入“批量采集”阶段时,以下问题会被放大:
(1)IP使用模式异常
- 单个 IP 持续高频请求
- 多个账号共用同一 IP
- IP 短时间无规律切换频繁
结果通常是直接封 IP 或返回验证码
(2)请求路径不符合用户行为
- 每次都直接访问目标数据页
- 没有“首页 → 列表 → 详情”的浏览过程
- 不加载图片、JS 等资源
结果通常是被识别为“非真实用户访问”
(3)会话与身份不匹配
- Cookie 与 IP 不一致
- 登录状态频繁变动
- 同一账号在多个地区 IP 登录
结果通常是账号风控或强制验证
2. 如何针对性提升自动化脚本成功率?
针对上面几个问题,解决方案也很简洁明了:
(1)设计符合真实用户的采集路径
- 模拟用户浏览路径,例如:首页 → 分类页 → 列表页 → 详情页
- 控制页面停留时间和操作节奏
(2)遵循正常的IP轮换频率
很多人误以为“频繁换 IP 就安全”,但实际上:
- 登录态任务:需要使用固定 IP,频繁变动IP会触发平台风控
- 规模化数据采集:需要使用轮换 IP 分散访问压力
- 多账号防关联:同一 IP 不要承载过多账号或任务
在实际项目抓取中,开发者往往不希望在维护 IP 池上耗费过多精力。因此,像IPFoxy 提供的动态住宅代理方案成为了许多团队的首选。IPFoxy拥有9000万以上真实住宅IP,覆盖200+国家,不仅支持按请求轮换和粘性会话,重复率低,而且IP来源真实,能够有效规避平台反爬机制的识别。
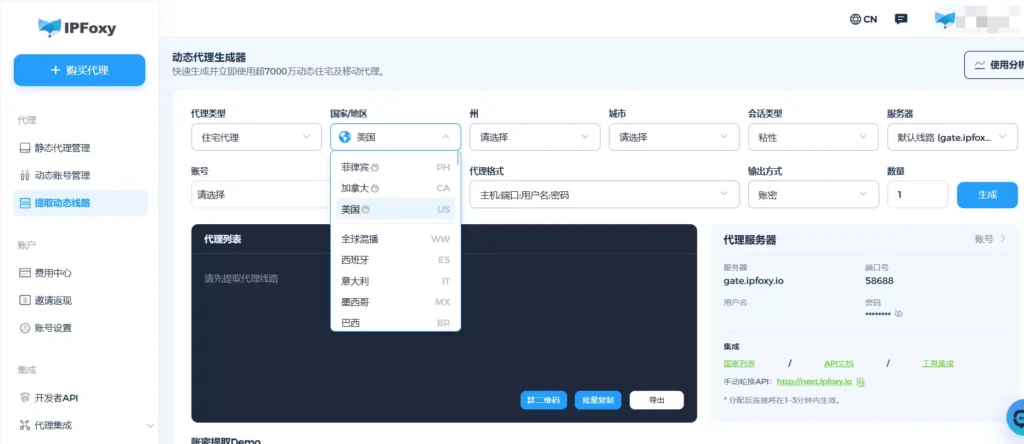
(3)降低自动化识别概率
- 引入随机抖动:在请求之间设置
0.5s - 3s的随机延迟,破坏固定的时间间隔。 - 请求头随机化:不仅是随机切换 User-Agent,还要配合不同的
Accept-Language、Sec-CH-UA等浏览器特有字段。 - TLS 指纹对齐:使用支持修改 TLS 栈的工具,确保你的 Playwright 请求在底层握手特征上与你所模拟的 Chrome 版本完全对齐。
五、FAQ
多数是因为 缺少浏览器依赖库 或 硬件加速(GPU)缺失。Playwright 用户建议直接使用官方 Docker 镜像;Puppeteer 需手动安装依赖。
可以利用 Playwright 的 BrowserContext 在单实例中实现环境隔离;同时用 page.route() 屏蔽图片、字体等静态资源。
可以在 Context 配置中禁用 WebRTC,并配合纯净住宅 IP 确保 DNS 解析一致性。
六、总结
总体来看,Playwright 与 Puppeteer 并不存在绝对的优劣,关键在于使用场景。前者更偏向工程化与规模化爬虫,后者则在轻量级自动化任务中依然高效可靠。
在实际项目中,工具只是基础,真正决定爬虫稳定性的,是整体策略设计,包括环境模拟、IP管理以及请求行为控制。只有将工具能力与爬虫策略结合,才能在复杂网站环境中实现长期稳定的数据采集。

