自动化抓取(Automation Crawling / Web Scraping)是数据驱动时代的核心能力——
无论是做电商价格监控、SEO分析、广告验证,还是AI训练数据采集,“抓数据” 都是第一步。
但越来越多的开发者发现:
- 同样的脚本,昨天还能跑,今天就被封;
- 换了User-Agent,还是403;
- 设置了代理池,几分钟后全被ban。
本文将带你解析自动化抓取被封的5大核心原因,以及如何用正确的策略与服务来突破封锁、稳定运行。
一、反爬机制的进化:从简单规则到智能识别
早期的网站反爬,只会检测:
- 请求频率过高;
- UA(User-Agent)固定;
- 无Referer或Cookie。
但现在,主流网站(如Amazon、Google、Reddit、Booking、LinkedIn)
都采用了多维度检测机制,包括但不限于:
| 检测维度 | 说明 |
| IP信誉 | 判断访问IP是否为代理、VPN、云机房出口等可疑来源 |
| 指纹信息 | 包括Canvas、WebGL、字体、语言、时区等浏览器指纹差异 |
| 行为轨迹 | 鼠标轨迹、滚动节奏、点击间隔、停留时长 |
| Session一致性 | 是否在短时间内使用不同IP/UA访问同账号 |
| 地理位置匹配 | 登录IP是否与账户国家或语言不符 |
换句话说,现在的反爬检测已经不只是“请求太多被封”,而是通过 AI + 风控模型 判断“你像不像人”。
二、脚本容易被封的5大常见原因
1、IP质量问题
- 请求频率过高: 在极短时间内从同一个IP地址发出大量请求,这是最典型的爬虫行为,无异于“自报家门”。
- IP质量低劣: 使用公开、免费的代理或数据中心的IP,这些IP段早已被各大网站列入黑名单,一旦使用,秒封是常态。
- IP关联性: 即使频率控制得当,但如果长期使用少数几个IP进行抓取,行为模式依然会被分析并封锁。
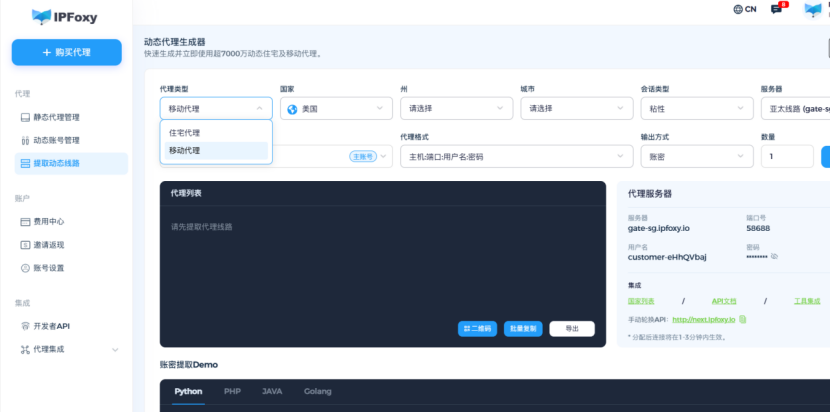
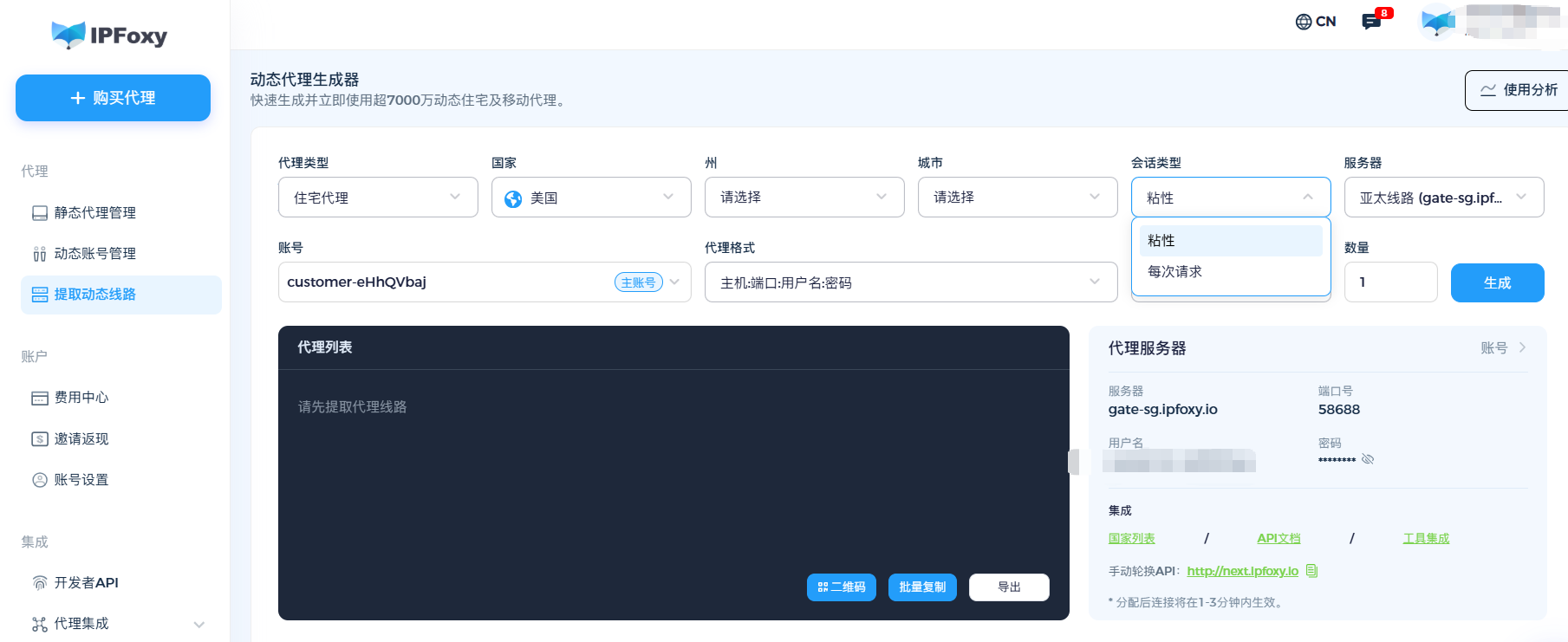
✅ 解决方案:使用高质量的住宅代理,比如IPFoxy住宅代理网络
- 支持 200+ 国家,9000万+ 实时住宅IP池,足够大的IP池可以减少重复率
- 动态、静态IP选择,适合不同类型业务脚本
- 动态IP与粘性控制:动态代理可自定义粘性时长
- 提供简洁的API接口,可以实现脚本集成,按请求、按时间或自动定时切换IP
- 住宅IP > 机房IP原则,住宅IP来自真实的ISP,与普通用户无异,是最佳选择。机房IP虽然便宜,但极易被识别和封锁
2、请求间隔异常
很多人以为“频繁换IP”就安全,实际上未必。网站不仅会识别IP段,也会检测访问连续性。如果同一个Session短时间内更换多个IP,也会被标记为“异常行为”。
✅ 解决方案:IPFoxy 的动态住宅代理支持自定义粘性时长(30/60min),这样既能保持IP连续性,又能避免长期复用同一IP,同时使用分布式队列,分散请求节奏。
3、指纹信息不一致
你可能已经更换了IP,却依然被封?那是因为浏览器指纹暴露了你。网站会读取你的:
- Canvas / WebGL 渲染参数;
- 字体库;
- 分辨率;
- User-Agent;
- 时区、语言、系统版本等。
这些数据组合能精确地标识一台设备。当多个脚本共享相同的指纹参数时,系统能立刻识别出“批量访问行为”。
✅ 建议:
结合指纹浏览器(如AdsPower / 比特指纹浏览器/ MaskFog等)进行多环境隔离,
为每个抓取任务分配独立设备参数。
再配合IPFoxy高质量代理,“IP + 指纹”双维伪装更自然。
4、请求模式太机械
很多开发者习惯使用固定间隔(如 1s / request)的请求逻辑。
但实际用户的行为是随机的。
统一节奏的访问,反而最容易被风控模型识别。
✅ 建议:
- 模拟人类操作节奏(随机延迟、滚动、停顿);
- 对不同页面采用不同访问频率;
- 分散时间段执行任务,避免集中爆发。
5、Cookie 与 Session 未隔离
当你在同一设备或同一IP下运行多个爬虫时,
如果Cookie、Session、LocalStorage共享,
平台会直接判定这些账号存在“同源访问”行为。
✅ 建议:
- 使用独立环境保存每个Session;
- 定期清理或更换Cookie;
- 采用代理 + 环境隔离的方式执行不同账号任务。
三、总结
脚本被封,不代表网站“太狠”,更多时候是你的环境“不像人”。如果你想让爬虫跑得久、跑得稳、跑得安全,从优化网络身份开始,就是最划算的一步。

