在全球跨境电商和 AI 数据分析的时代,谁能快速理解海外用户需求,谁就能抢占市场先机。Quora 作为一个高质量的问答社区,不仅汇集了大量真实用户提问和讨论,还经常出现在 Google 搜索结果的前列。对跨境卖家来说,它是获取自然流量和市场洞察的宝库;对 AI 从业者来说,它是训练模型、构建垂直知识库的丰富数据源。
本文将带你系统了解如何抓取 Quora 数据,帮助跨境卖家精准洞察海外买家需求,同时为 AI 模型训练和知识库构建提供高质量结构化数据。
一、Quora的数据爬取:有何价值?
很多跨境卖家和 AI 从业者在工作中会遇到海外买家需求难以精准把握、缺乏可靠海外数据等问题。Quora作为国外最大的知识问答网站,其问答内容专业且高质量覆盖各种产品、行业和使用场景。
- 跨境电商:抢占 SEO 流量红利
Quora 问答页在 Google 上常常霸屏。抓取热门回答,既能优化你的网站内容,还能借助 Quora 自身权重吸引精准买家,让你的产品被潜在客户“一眼看到”,自然流量轻松拉满。 - 用户需求与市场洞察:看懂海外买家心声
分析Quora用户提问和讨论,直接洞察他们的痛点和偏好:物流慢?产品质量差?选品难?掌握这些信息,你就能精准调整策略,避开踩雷,提高转化率,做出买家真心想买的产品。 - AI 行业:训练模型 & 构建知识库
把抓来的Quora问答整理成结构化文本,不仅能喂给大语言模型(LLM)训练,也能打造垂直领域知识库,让 AI 在特定主题上回答更专业、更靠谱。研究趋势、做数据分析,一键搞定。
二、Quora 数据爬取教程:分布操作
第一步: 工具准备
在开始抓取 Quora 问答内容之前,需要先搭建一个稳定、可控的爬取环境,核心目标是:模拟真实用户行为 + 处理动态内容 + 降低反爬风险
Python安装:Python 版本建议 3.10 及以上+ 确保本地或服务器环境已正确安装
Python库安装:
- Selenium
用于自动化浏览器操作,模拟真实用户访问 Quora 页面,解决 JavaScript 动态加载问题。 - BeautifulSoup(bs4)
用于解析 HTML 结构,从复杂的页面中提取问题、答案、点赞等核心数据。 - Selenium-wire
扩展 Selenium 的网络请求能力,使其支持代理配置,便于接入 ScraperAPI 等代理服务,绕过反抓取限制。
第二步: 理解 Quora 页面结构
在写代码之前,必须先搞清楚 Quora 的内容是如何组织的,以便识别包含问答数据的关键。
- 选定目标问题相关的回答。本文以 Quora 上问题“What is the easiest way to learn to code?”为例,抓取该问题下的所有自然回答。
- 使用开发者工具(右键单击网页并选择“检查”)来查看HTML 结构,接着找到包含我们所需数据的 HTML 元素。
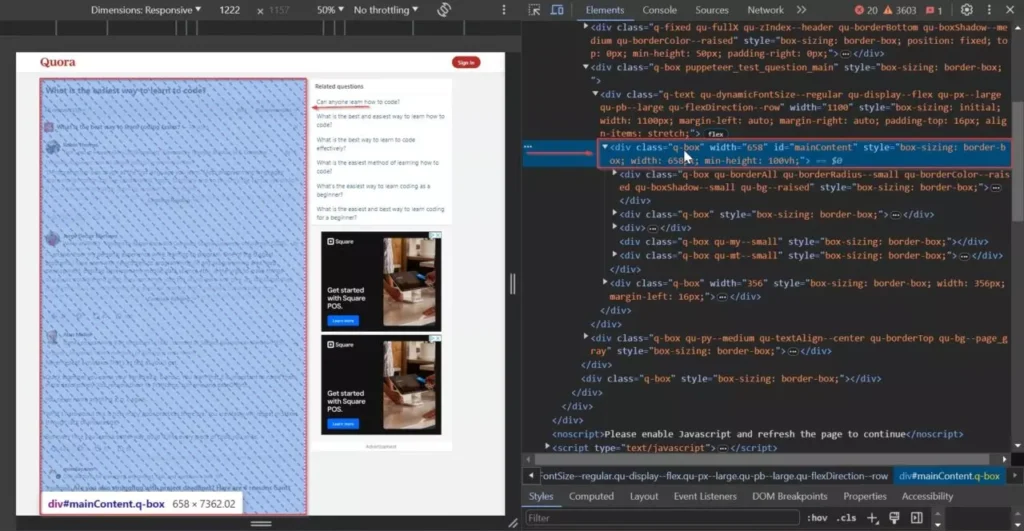
- div#mainContent:包含页面中所有问题与答案,是爬取的入口节点。
- 问题文本元素:提取当前讨论的问题标题。
对应div class:div.q-text.qu-dynamicFontSize–regular_title
- 答案内容元素:包含用户回答答案的文本。
对应div class:div.q-box.spacing_log_answer_content.puppeteer_test_answer_content
- 点赞数元素:位于答案的父级节点中,用于衡量回答受欢迎程度。
对应span class:span.q-text.qu-whiteSpace–nowrap…
- 广告答案标识:用于区分推广内容,后续需过滤,确保数据“干净”。
对应div class:div.q-box.dom_annotate_ad_promoted_answer
第三步:将数据导入库
- Selenium / seleniumwire → 自动打开网页、模拟滚动和点击
- BeautifulSoup → 解析 HTML 提取数据
- csv → 保存抓取结果
- time → 模拟人工操作的等待
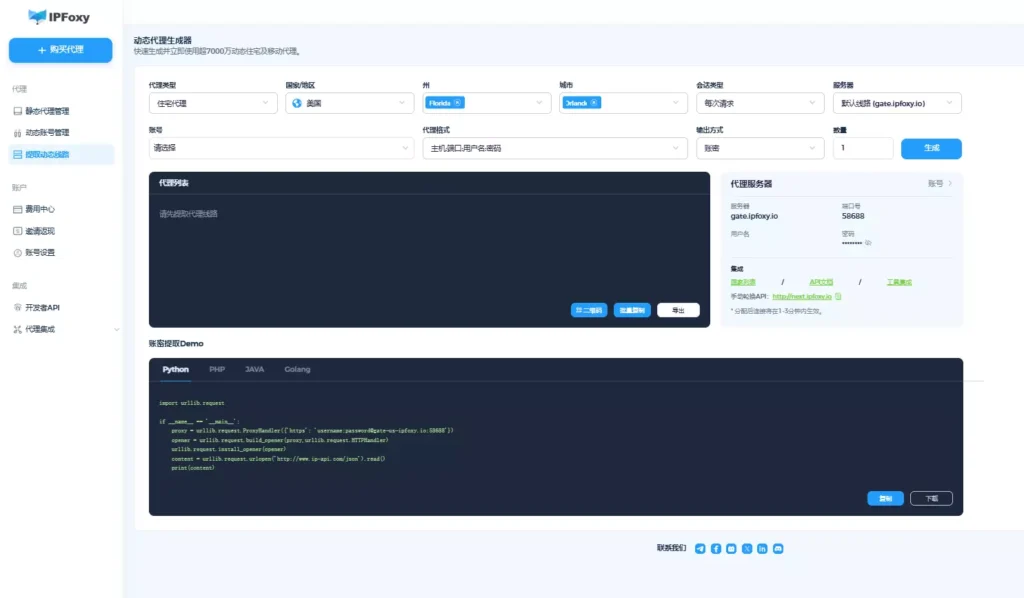
第四步:配置代理(Selenium Wire + IPFoxy)
通过代理访问 Quora,避免被封或限制,确保抓取稳定。动态住宅代理可以让请求看起来像真实用户在用浏览器访问,并支持按时间轮换IP从而躲掉反爬限制。我们测试了IPFoxy动态代理池,其质量与功能优势在此类场景中表现明显:
- IP 轮换与粘性会话:支持 15–30 分钟轮换的粘性 IP,在加载完整问题页面、滚动多条回答或翻页访问时,保持会话一致性,降低触发风控的风险。
- 大规模 IP 池与高并发:可支持无限并发请求,并提供超过9000万个 IP,可自定义地理位置与协议。
- 批量 API 调用:结合批量访问,可在长时间、大规模抓取多个 Quora 问题页面时保持高成功率,同时降低账号关联或封禁风险。
第五步:滚动页面加载动态内容
- Quora 的答案是动态加载的,不滚动页面抓不到全部内容。
- scroll_to_bottom() 函数模拟按 End 键,让页面往下滚动直到底部,确保所有答案显示。
第六步:用 BeautifulSoup 提取数据
- 把 Selenium 打开的网页源码交给 BeautifulSoup 解析。
- 定位关键元素:问题 div、答案 div、点赞数 span,过滤掉广告答案。
- 作用:把 HTML 结构化成可处理的数据对象。
第七步:保存数据到 CSV
- 把提取的“问题文本、答案文本、点赞数”写入 CSV 文件,方便后续分析。
- 如果某些数据缺失,自动填默认值(如“0”或“无答案”)。
第八步:执行抓取脚本
- 打开 Chrome 浏览器,加载目标 Quora 问题页面。
- 等待页面加载 → 滚动到底 → 提取答案 → 保存 CSV。
- 用 try-except-finally 确保即使发生错误,也能优雅关闭浏览器。
三、常见FAQ
Quora 汇集了大量高质量的问答内容,覆盖各种产品、行业和使用场景。抓取这些数据可以帮助跨境卖家洞察海外买家痛点、优化产品策略、提升 SEO 排名,也能为 AI 模型训练或构建知识库提供可靠的结构化数据,让分析和决策更精准高效
是的,Quora 会检测异常访问行为,比如频繁刷新、快速翻页或同一 IP 短时间访问大量页面。这些行为会触发反爬机制,导致验证码、访问限制甚至账号封禁。合理使用代理、模拟真实浏览行为和控制访问频率可以有效绕过这些限
在抓取像 Quora 这样的大流量网站时,如果每次请求都来自同一个 IP,网站很容易判断这是自动化行为,从而限制访问甚至封禁账号。添加代理可以模拟不同用户访问,使抓取更稳定、更安全,同时减少被风控干扰的风
四、结语
抓取 Quora 数据可以帮助你更好地了解海外市场和用户需求,无论是跨境电商还是 AI 数据分析都能从中获益。把数据整理和分析后,你可以发现热门问题、用户痛点,优化产品策略和内容布局,也能构建高质量的知识库,提高 AI 模型的专业性和准确性。掌握方法后,Quora 的问答数据就能真正成为你的决策助手,让业务和项目更高效、更精准、更有竞争力。

