亚马逊数据抓取是选品分析、价格监控和竞品研究的重要手段。随着 2026 年平台风控升级,传统爬虫方式已经难以稳定运行。
本文将从实战角度出发,简要讲解亚马逊数据抓取的核心流程,包括数据类型、技术挑战以及可运行的抓取方案。
一、为什么要批量抓取亚马逊商品数据?亚马逊可以抓取哪些数据?
1、为什么要批量抓取亚马逊商品数据?
批量抓取 Amazon 数据可以高效获取市场信息,并基于数据进行决策,而不是依赖经验判断。同时,自动化抓取相比手动方式效率更高,也更适合长期监控。
2、亚马逊可以抓取哪些数据?
亚马逊 可抓取的数据类型较为丰富,主要包括以下几类:
- 商品基础数据:包括商品标题、品牌、类目、ASIN、描述和图片等,用于产品分析和建档。
- 价格数据:包括当前价格、折扣信息等,可用于价格监控和动态定价。
- 评论与评分数据:包括评论内容、评分、评论数量等,适用于用户反馈分析和产品优化。
- 排名与销售信息:如 Best Seller Rank(BSR)和类目排名,用于判断产品热度。
- 搜索结果数据:包括关键词排名和搜索结果列表,有助于优化曝光和广告策略。
- 卖家与库存信息:如卖家信息、库存状态和配送方式,用于竞争分析和供应链判断。
二、2026 亚马逊商品数据抓取的技术挑战
在实际操作中,亚马逊数据抓取并非简单的页面采集。随着平台风控不断升级,数据抓取面临越来越多的技术挑战。
1. 反爬机制严格,容易触发封禁
亚马逊 对异常访问行为非常敏感,例如高频请求、重复IP访问或非正常浏览路径,都可能触发风控机制,导致被封或请求被限制。
2. CAPTCHA 验证频繁出现
在抓取过程中,亚马逊 会通过验证码识别可疑流量。一旦触发 CAPTCHA,将严重影响数据采集效率,甚至导致任务中断。
3. IP 封锁与请求限制
使用单一IP或低质量代理时,很容易被识别并限制访问。
4. 页面结构动态变化
亚马逊 页面结构并非固定,HTML标签和数据位置可能随时调整。这会导致已有的爬虫规则失效,需要持续维护和更新解析逻辑。
5. 动态内容加载(JavaScript 渲染)
部分数据通过 JavaScript 动态加载,传统请求方式无法直接获取,需要借助浏览器自动化工具或渲染技术,增加了开发成本。
6. 请求频率与并发控制难度高
为了避免被封,需要对请求频率进行严格控制。但过低的抓取速度又会影响数据获取效率,因此需要在稳定性与效率之间找到平衡。
7. 数据清洗与结构化难度大
抓取到的原始数据往往存在冗余、不规范或缺失问题,需要进行清洗、去重和结构化处理,才能用于后续分析。

三、如何批量抓取亚马逊商品数据?
在实际开发中,亚马逊 数据抓取通常不是一步完成的,而是一个逐步搭建的过程。下面按照从基础到可运行的流程,给出一套清晰的实现路径。
第一步:确定抓取目标
在动手之前,需要明确抓取范围和数据字段:
- 抓取对象:商品页(ASIN)、搜索结果页或类目页
- 核心字段:标题、价格、评分、评论数等
这一步会直接影响后续代码结构和抓取效率。
第二步:实现基础抓取逻辑
先验证页面是否可以正常获取:
import requests
from bs4 import BeautifulSoup
url = "https://www.Amazon.com/dp/B0XXXXXXX"
headers = {
"User-Agent": "Mozilla/5.0"
}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
title = soup.select_one("#productTitle")
print(title.get_text(strip=True) if title else "No Title")这一阶段的目标是确认页面结构和数据位置。
第三步:接入动态代理
当开始批量抓取时,如果仍然使用单一IP,很容易触发亚马逊风控,因此需要接入支持动态切换的住宅代理。
如果是刚开始做 亚马逊 抓取,建议直接使用成熟的代理服务而不是自己维护代理池,能够大幅降低维护成本,尤其适合中大型抓取项目。一方面可以节省大量时间,另一方面稳定性也更容易保障。例如IPFoxy这样住宅代理服务商,提供90M+低滥用率住宅代理IP池,在连续抓取、并发请求场景实测高性能,可以通过IPFoxy动态面板配置代理地区、代理轮换频率、代理格式、代理协议等信息,获取可配置的代理信息。
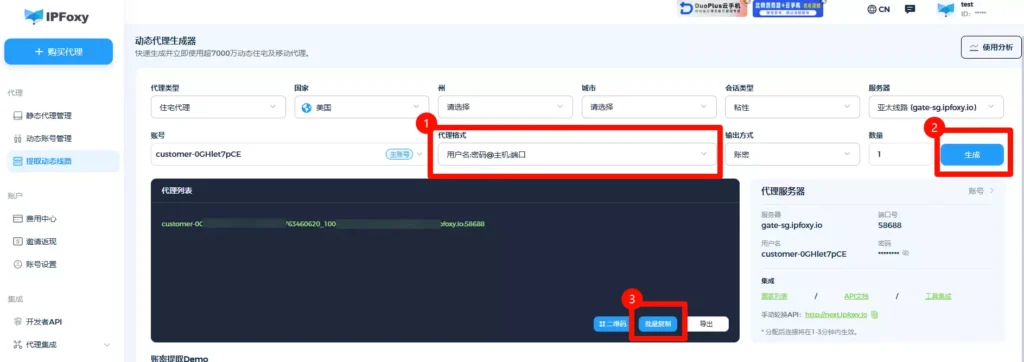
以 Python 为例,将刚刚从IPFoxy获取的代理连接信息粘贴到代码上,如代理连接信息是:username:password@gate-us-ipfoxy.io:58688,完成动态代理配置,执行代码后,就可以从日志看到出口IP已经改变。
import requests
from requests.auth import HTTPProxyAuth
if __name__ == '__main__':
proxy = urllib.request.ProxyHandler({
'https': 'username:password@gate-us-ipfoxy.io:58688',
'http': 'username:password@gate-us-ipfoxy.io:58688',
})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
content = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(content)第四步:实现批量抓取
在单个请求稳定后,可以扩展为批量任务:
from concurrent.futures import ThreadPoolExecutor
urls = [
"https://www.Amazon.com/dp/ASIN1",
"https://www.Amazon.com/dp/ASIN2"
]
def fetch(url):
global headers, proxies # 或者使用闭包
try:
response = requests.get(url, headers=headers, proxies=proxies, timeout=10)
return response.status_code
except Exception as e:
return f"Error: {e}"
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(fetch, urls))
print(results)需要注意控制并发数量,避免请求过快。
第五步:使用 Docker 部署
为了方便长期运行,可以将项目容器化:
FROM python:3.11-slim
WORKDIR /app
COPY . .
RUN pip install requests beautifulsoup4
CMD ["python", "main.py"]运行:
docker build -t Amazon-scraper .
docker run Amazon-scraper第六步:结构化抓取任务
对于更复杂的项目,可以使用配置化方式管理抓取规则:
{
"name": "Amazon_product",
"start_urls": ["https://www.Amazon.com/dp/{asin}"],
"fields": {
"title": "#productTitle",
"price": ".a-offscreen"
}
}四、如何提高批量抓取亚马逊的成功率与效率?
在完成基础抓取流程后,下一步的重点就是提升整体的稳定性和效率。下面几个优化点可以直接在第三部分的代码基础上进行增强。
1、优化请求头,降低被识别概率
可以进一步完善请求头,模拟真实浏览器行为:
headers = {
"User-Agent": "Mozilla/5.0",
"Accept-Language": "en-US,en;q=0.9",
"Connection": "keep-alive"
}建议配合随机 User-Agent 使用,避免所有请求特征一致。
2、控制并发 + 随机延迟
在第四步的并发代码中,不建议一味提高线程数,可以加入延迟控制:
import time
import random
def fetch(url):
time.sleep(random.uniform(1, 3))
global headers, proxies # 或者使用闭包 try: response = requests.get(url, headers=headers, proxies=proxies, timeout=10) return response.status_code except Exception as e: return f"Error: {e}"这样可以有效降低触发风控的概率,同时提高长期稳定性。
3、优化代理轮换策略
动态代理在脚本执行中尽量做到避免同一IP短时间内重复访问同一ASIN,因此需要控制单个IP的请求频率。
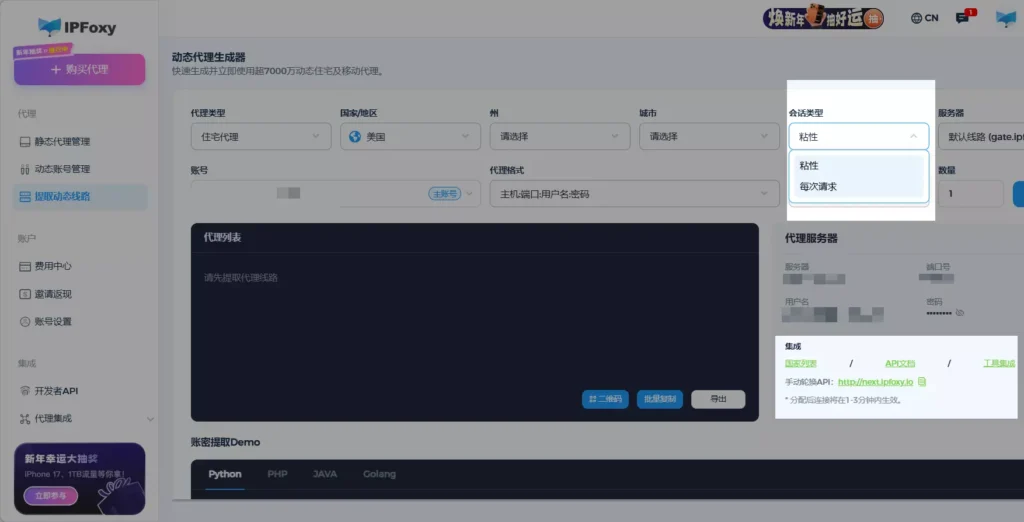
例如 IPFoxy 提供几种常用轮换模式:
- 粘性会话(Sticky Session):在一定时间内保持同一 IP,适合需要连续访问(如翻页、评论抓取),支持30分钟-24小时自主配置。
- 按请求轮换(Rotating per Request):每次请求自动切换 IP,适合大规模并发抓取
- 手动切换:需要通过手动切换API完成。
这种组合可以根据不同抓取场景灵活切换,更接近真实用户行为,适配不同自动化采集架构。
4、增加失败重试机制
抓取过程中出现超时或返回异常是常见情况,建议加入重试逻辑:
def fetch_with_retry(url, retries=3):
for i in range(retries):
try:
response = requests.get(
url,
headers=headers,
proxies=proxies,
timeout=10
)
if response.status_code == 200:
return response.text
elif response.status_code in [403, 503]: # 被封或限流
print(f"尝试 {i+1} 失败,状态码: {response.status_code}")
time.sleep(2 ** i) # 指数退避
else:
return None
except Exception as e:
print(f"请求异常: {e}")
time.sleep(2 ** i)
return None可以有效提升整体任务完成率。
5、精简解析逻辑,提高性能
在解析阶段,只提取必要字段即可:
title = soup.select_one("#productTitle")
price = soup.select_one(".a-offscreen")避免不必要的解析,可以减少资源消耗,提高抓取效率。
五、常见FAQ
大多数商品页数据不需要登录即可获取,但频繁访问时仍可能触发验证,因此仍需配合代理和请求控制。
通常是因为页面被风控拦截或内容未完全加载。可以检查返回状态码,或切换代理后重试。
简单页面优先用 requests,速度更快;如果遇到动态加载或结构复杂的页面,再考虑使用浏览器自动化工具。
六、总结
整体来看,亚马逊 数据抓取的关键在于稳定性与效率的平衡。通过合理的请求策略、代理配置和并发控制,可以实现持续、可靠的数据采集。
在实际项目中,建议从简单方案开始,逐步优化,最终搭建一套可长期运行的自动化抓取系统。

