在当下的数据驱动环境中,LinkedIn 已成为获取职业与商业信息的重要平台。无论是销售获客、市场调研还是用户分析,LinkedIn数据都具有较高价值。
但由于平台限制较多,手动获取效率低,因此越来越多开发者选择使用 Python 进行自动化抓取。本文将围绕LinkedIn数据抓取,从工具选择、实现方法到实战代码,提供一套完整思路。
一、什么是LinkedIn数据抓取?
LinkedIn 数据是指该平台上公开展示的职业与商业信息,数据具有较高的商业价值,广泛应用于销售线索获取、市场调研和用户分析等场景。
常见的采集数据类型包括:
- 用户数据:姓名、职位、工作经历、技能等
- 公司数据:公司名称、行业、规模、招聘信息
- 内容数据:帖子、评论、点赞等
LinkedIn 平台在数据获取上存在限制,例如无法批量导出、搜索结果受限等,因此,许多用户借助数据抓取实现高效采集,以满足获客与市场分析等需求。
在技术实现上,Python 是主流选择,具备开发门槛低、支持动态页面解析、便于自动化处理等优势,适合用于规模化抓取 LinkedIn 数据。

二、Python抓取LinkedIn数据的方法
使用 Python 抓取 LinkedIn 数据,通常需要根据页面结构和抓取规模选择不同方案。常见方法包括以下几种:
1.Requests + 解析库(基础方式)
通过发送HTTP请求获取页面源码,再使用解析库提取数据。
- 常用工具:requests和BeautifulSoup
- 适用场景:简单页面或部分公开数据
- 局限:难以处理LinkedIn的动态加载内容
2.Selenium / Playwright(浏览器自动化)
通过模拟真实用户操作浏览器,实现登录、搜索和数据提取,这种方法支持JavaScript渲染,还可以模拟真实行为,稳定性较高。
其中,Playwright在性能和反检测能力上通常优于Selenium,更适合大规模采集。
3.Scrapy框架(规模化抓取)
Scrapy适合构建高效率的数据采集系统,常用于批量抓取任务。这种方法高并发、可扩展性强,通常需要结合Playwright或Selenium处理动态页面
4.API与第三方工具
通过API或现成工具快速获取结构化数据,可以降低开发成本,但是,这种方法数据范围容易受限并且成本较高。
在实际项目中,LinkedIn数据抓取通常采用组合方案:使用Playwright或Selenium处理动态页面,再结合Scrapy实现规模化采集。同时,为了保证稳定性,通常建议配合代理IP与配合合理的请求策略。
三、Python实战:如何抓取LinkedIn数据?
下面以上述方法中的Python + Playwright 为例,演示基本抓取流程,并分别演示不同场景的数据抓取方法。
1.使用Playwright获取页面内容
由于 LinkedIn 采用动态加载机制,直接请求往往无法获取完整数据,因此需要先渲染页面。
pip install playwright
playwright installfrom playwright.sync_api import sync_playwright
def get_page_content():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
# 打开登录页
page.goto("https://www.linkedin.com/login")
input("请手动登录后按回车继续...")
# 进入搜索结果页(示例关键词)
page.goto("https://www.linkedin.com/search/results/people/?keywords=marketing")
# 等待页面加载
page.wait_for_timeout(5000)
html = page.content()
browser.close()
return html
html = get_page_content()
print(html[:500])实际项目中建议使用storage_state保存登录状态,避免重复登录。
2.用户数据抓取(People)
用户数据主要用于获取潜在客户信息,例如姓名、职位等,通常来自搜索结果页,适合批量采集,但需要处理滚动加载与分页问题。
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
def scrape_people():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.linkedin.com/login")
input("登录后回车...")
page.goto("https://www.linkedin.com/search/results/people/?keywords=marketing")
page.wait_for_timeout(5000)
soup = BeautifulSoup(page.content(), "html.parser")
results = []
for item in soup.select(".entity-result"):
name = item.select_one(".entity-result__title-text")
title = item.select_one(".entity-result__primary-subtitle")
results.append({
"name": name.get_text(strip=True) if name else None,
"title": title.get_text(strip=True) if title else None
})
browser.close()
return results
3. 职位数据抓取(Jobs)
职位数据主要用于分析招聘需求和行业趋势,结构相对清晰,适合批量抓取,但在高频抓取时需要控制请求节奏。
def scrape_jobs():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.linkedin.com/login")
input("登录后回车...")
page.goto("https://www.linkedin.com/jobs/search/?keywords=python")
page.wait_for_timeout(5000)
soup = BeautifulSoup(page.content(), "html.parser")
jobs = []
for job in soup.select(".jobs-search-results__list-item"):
title = job.select_one(".job-card-list__title")
company = job.select_one(".job-card-container__company-name")
location = job.select_one(".job-card-container__metadata-item")
jobs.append({
"title": title.get_text(strip=True) if title else None,
"company": company.get_text(strip=True) if company else None,
"location": location.get_text(strip=True) if location else None
})
browser.close()
return jobs
4.公司数据抓取(Companies)
公司数据通常用于获取企业信息,如行业、简介等,常见于B2B分析场景,不过公司数据通常来自详情页,适合做精细化分析,而不是大规模抓取。
def scrape_company():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.linkedin.com/login")
input("登录后回车...")
page.goto("https://www.linkedin.com/company/google/")
page.wait_for_timeout(5000)
soup = BeautifulSoup(page.content(), "html.parser")
name = soup.select_one("h1")
about = soup.select_one(".org-page-details__definition-text")
data = {
"company": name.get_text(strip=True) if name else None,
"about": about.get_text(strip=True) if about else None
}
browser.close()
return data
5. 内容数据抓取(Posts)
内容数据包括用户发布的帖子和互动信息,适用于分析用户行为和内容趋势,数据动态性强,页面结构变化较频繁,需要持续维护解析规则。
def scrape_posts():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.linkedin.com/login")
input("登录后回车...")
page.goto("https://www.linkedin.com/feed/")
page.wait_for_timeout(5000)
soup = BeautifulSoup(page.content(), "html.parser")
posts = []
for post in soup.select(".feed-shared-update-v2"):
text = post.select_one(".break-words")
posts.append({
"content": text.get_text(strip=True) if text else None
})
browser.close()
return posts
从实际应用来看,不同类型的LinkedIn数据(用户、职位、公司和内容)在抓取流程上是统一的,但在页面结构和实现细节上存在差异。通过 Python 结合浏览器自动化工具,可以灵活应对这些场景。
四、LinkedIn数据抓取稳定方案:如何避免数据采集受限?
在实际测试中,常见触发Linkedln风控的情况包括:
- 短时间内高频访问页面
- 多账号共用同一IP
- 自动化行为过于规律
- 登录环境频繁变化
这些行为很容易被识别为异常操作,从而触发限制。在实践中,一般需要从请求策略和网络环境两方面进行优化。
1. 控制访问节奏
建议在脚本中加入随机延迟,避免固定频率请求:
import time
import random
def random_delay(min_s=2, max_s=5):
delay = random.uniform(min_s, max_s)
time.sleep(delay)
# 示例:翻页或点击前调用
page.goto("https://www.linkedin.com/feed/")
random_delay()
page.goto("https://www.linkedin.com/search/results/people/?keywords=marketing")
random_delay(3, 8)
如果是批量抓取任务,也可以控制整体节奏:
for i, url in enumerate(url_list):
page.goto(url)
random_delay(2, 6)
if i % 10 == 0:
time.sleep(random.uniform(10, 20)) # 每10次增加长休眠
这种方式可以明显降低因“请求过于规律”被识别的风险。
2. 配置动态住宅代理IP
网络环境是LinkedIn风控的重要判断依据之一,如果所有请求来自同一IP,很容易触发限制。在单账号场景下,引入代理IP即可显著降低风险。常见做法包括:
- 为请求配置独立IP
- 使用动态代理分散访问来源
以下是IPFoxy代理IP示例(Python)
可以通过IPFoxy动态IP面板设置IP所需参数,并生成可配置的代理信息粘贴到python代码上。
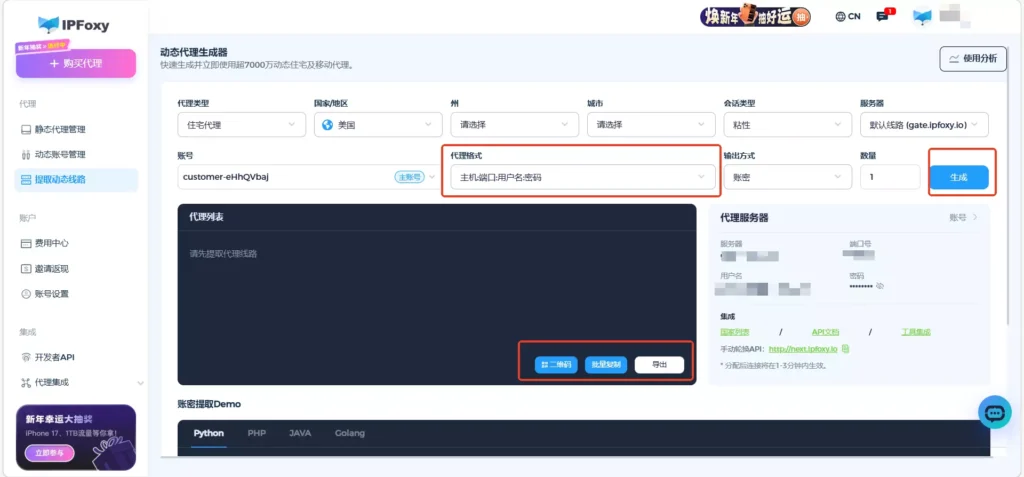
例如代理连接信息是:username:password@gate-us-ipfoxy.io:58688,那么代码示例为:
import urllib.request
if __name__ == '__main__':
proxy = urllib.request.ProxyHandler({
'https': 'username:password@gate-us-ipfoxy.io:58688',
'http': 'username:password@gate-us-ipfoxy.io:58688',
})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
content = urllib.request.urlopen('http://www.ip-api.com/json').read()
print(content)如果执行代码看到出口IP发生变化,说明代理已成功生效,接下来可以在 Playwright 中使用代理。
3. 模拟真实用户行为
除了控制频率,还可以通过模拟用户操作降低风险,例如滚动页面、随机停留等。
import random
def simulate_scroll(page):
for _ in range(random.randint(3, 6)):
page.mouse.wheel(0, random.randint(500, 1500))
page.wait_for_timeout(random.randint(1000, 3000))
def simulate_behavior(page):
# 随机滚动
simulate_scroll(page)
# 随机停留
page.wait_for_timeout(random.randint(2000, 5000))
# 示例调用
page.goto("https://www.linkedin.com/feed/")
simulate_behavior(page)
五、常见问题FAQ
抓取公开页面数据在多数情况下是允许的,但需要遵守 LinkedIn 的用户协议和相关法律法规。 建议仅用于数据分析、市场研究等合规场景,避免涉及隐私或商业滥用。
建议在抓取时就做好字段结构设计,方便后续分析使用。根据数据规模不同,可以选择不同方式:
小规模:CSV / JSON文件 中等规模:MySQL / PostgreSQL 大规模:MongoDB / 数据仓库
并不是。速度过快反而更容易触发风控。在实际项目中,更重要的是“稳定持续抓取”,而不是短时间内获取大量数据。
总结
总体来看,LinkedIn数据抓取不仅是技术问题,更涉及稳定性与策略设计。通过合理使用Python工具、优化抓取方式,并结合实际业务场景,可以实现高效且稳定的数据采集。

